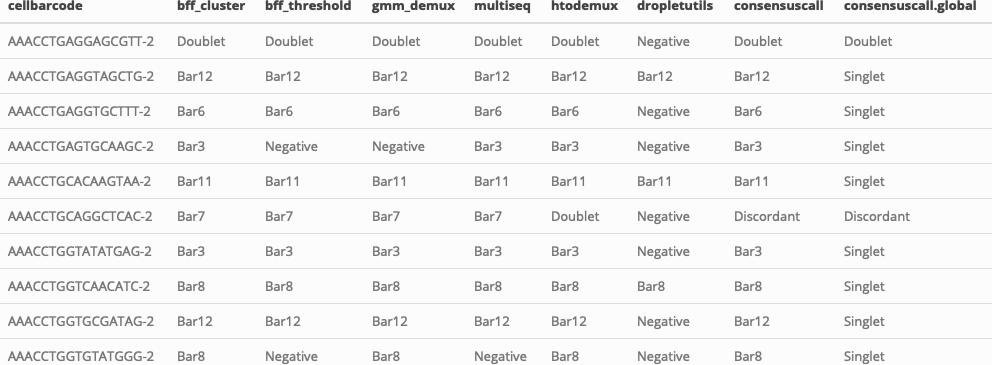
Benchmarking Demultiplexing Algorithms with cellhashR
Source:vignettes/V03-Benchmark-example.Rmd
V03-Benchmark-example.RmdThis vignette demonstrates how to use cellhashR to easily run multiple demultiplexing algorithms on cell hashing data in order to produce the type of classifications summarized in this figure from the BFF paper.
Generate Hashing Calls
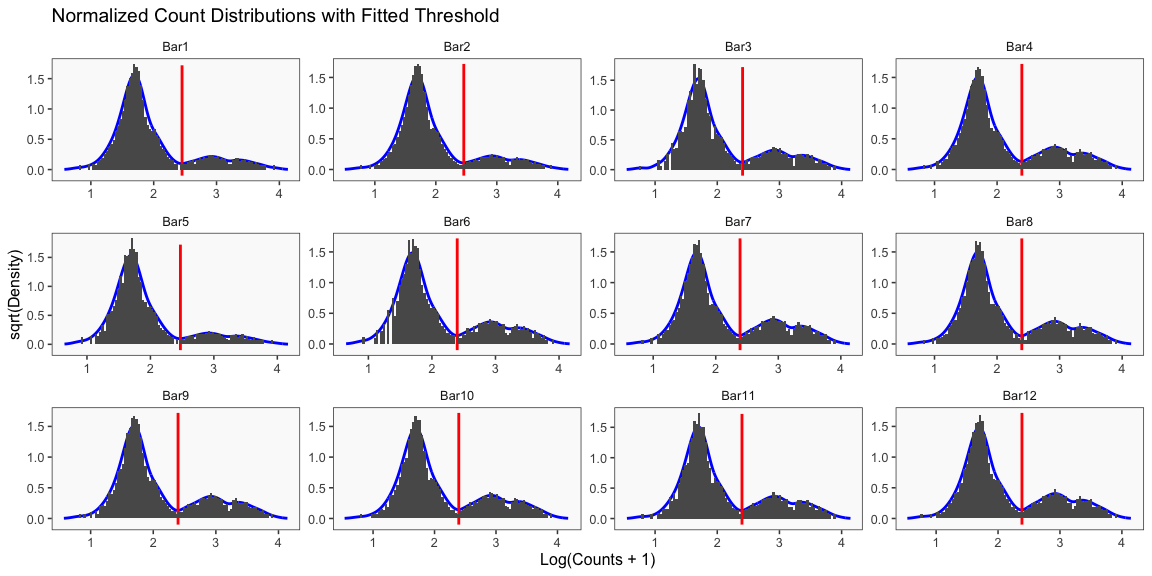
The cellhashR command GenerateCellHashingCalls performs demultiplexing analysis on the data using the algorithms listed in “methods”. The plots that follow are the most informative of the plots generated by each demultiplexing algorithm.
methods <- c("bff_cluster", "bff_raw", "gmm_demux", "multiseq", "htodemux", "dropletutils")
df <- GenerateCellHashingCalls(barcodeMatrix = barcodeData, methods = methods, cellbarcodeWhitelist = cellbarcodeWhitelist, metricsFile = metricsFile)
write.table(df, file = callFile, sep = '\t', row.names = FALSE, quote = FALSE)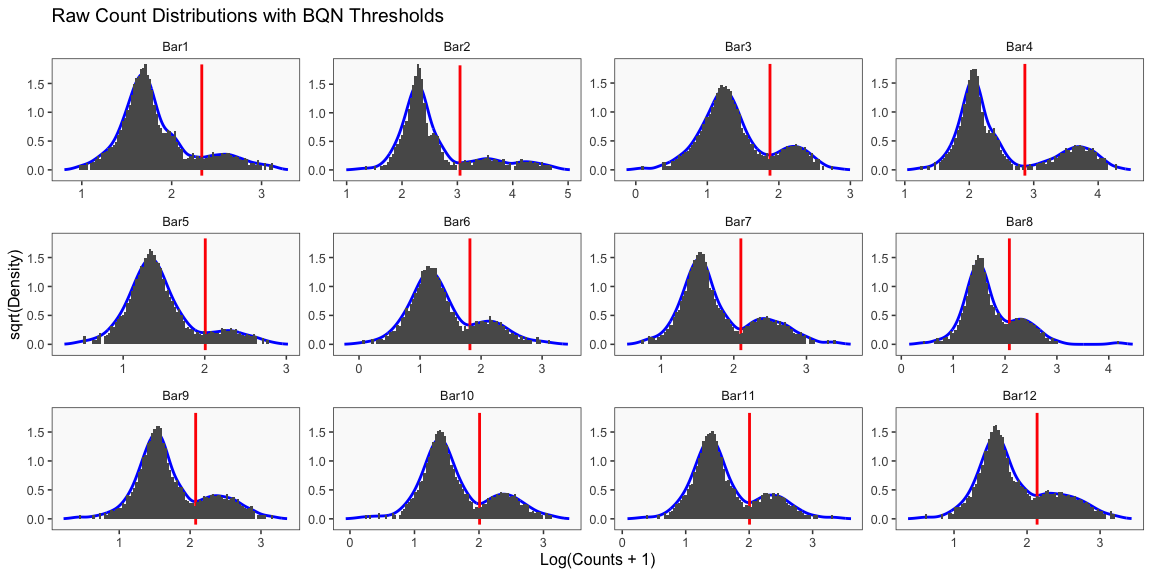
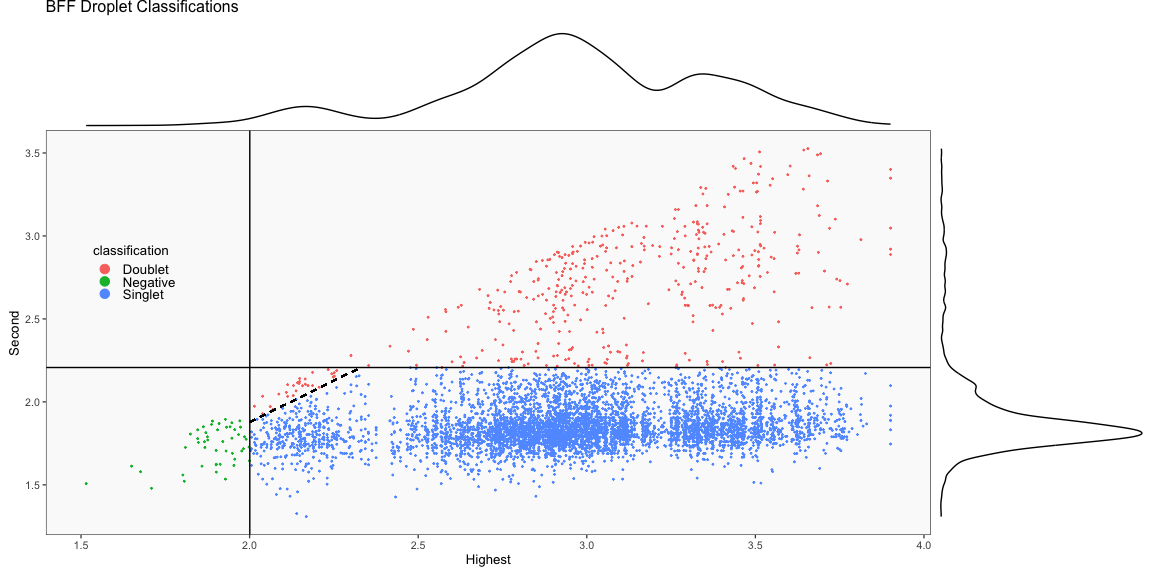
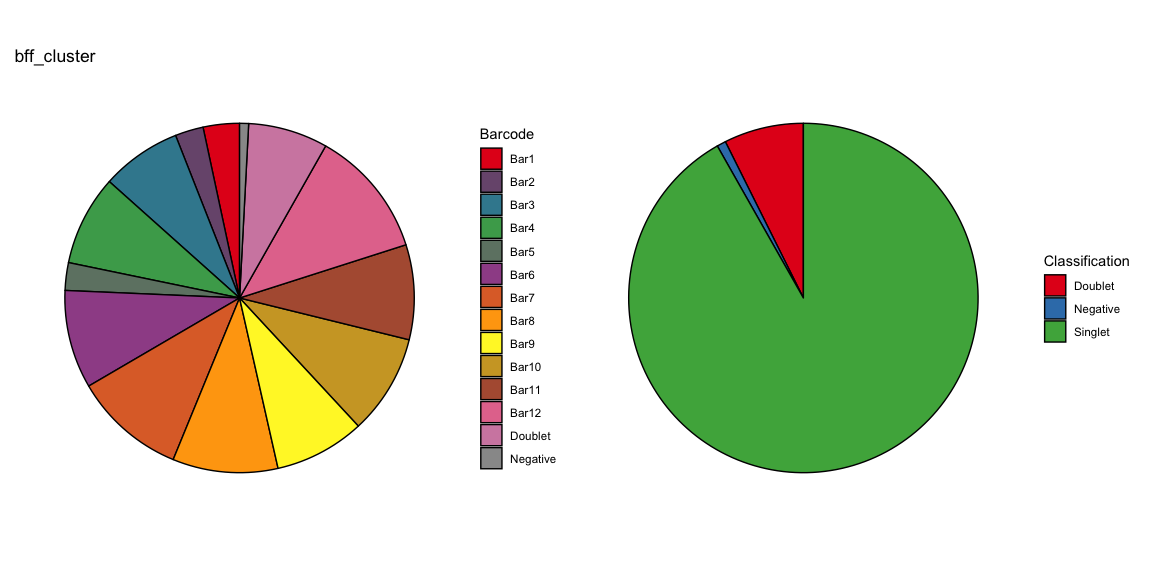
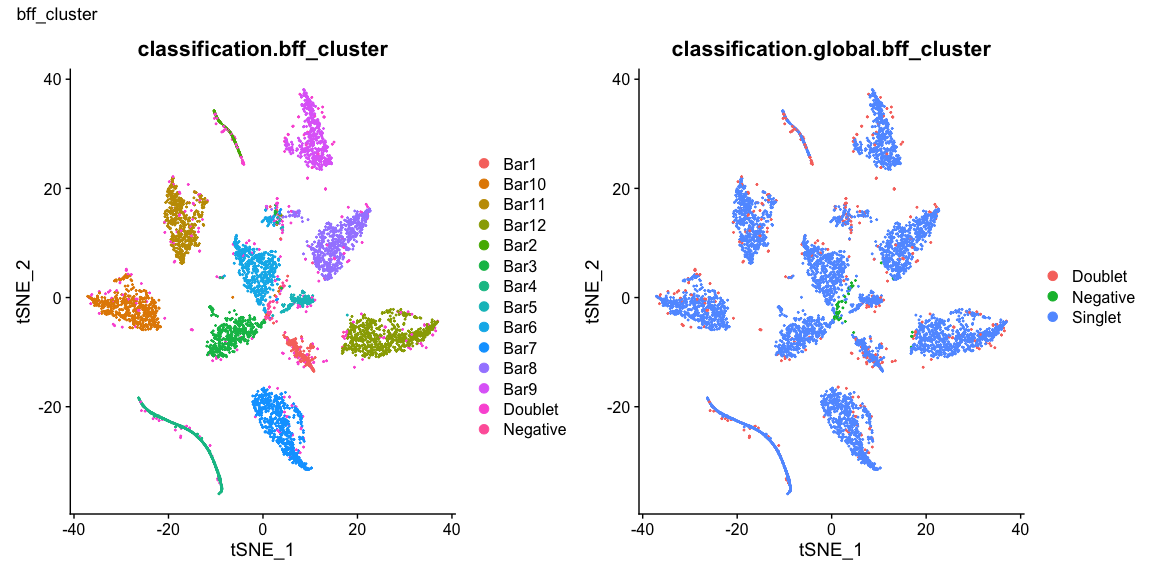
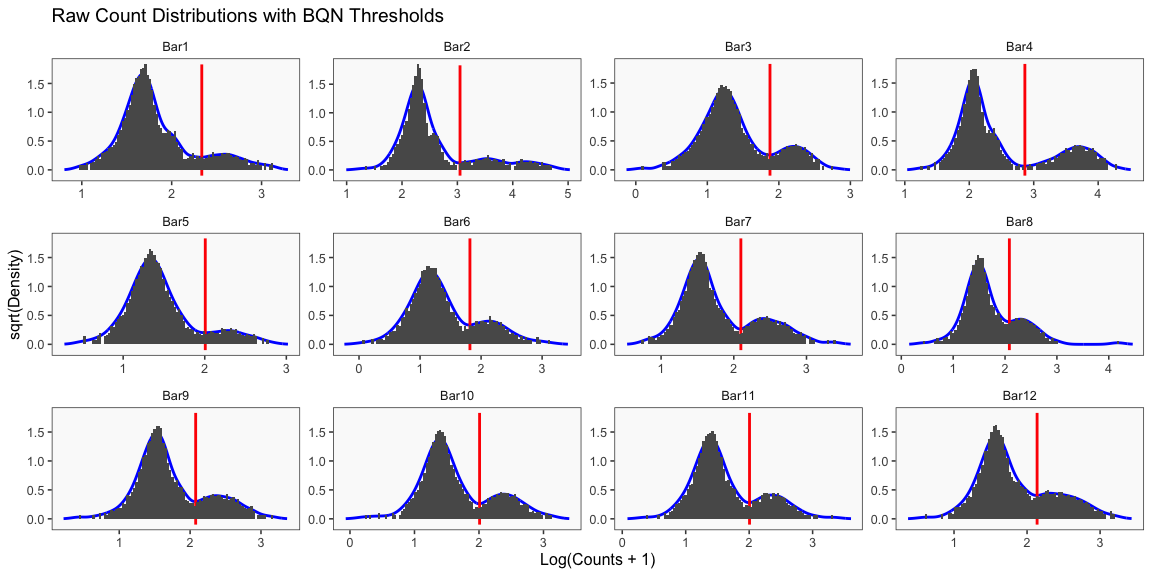
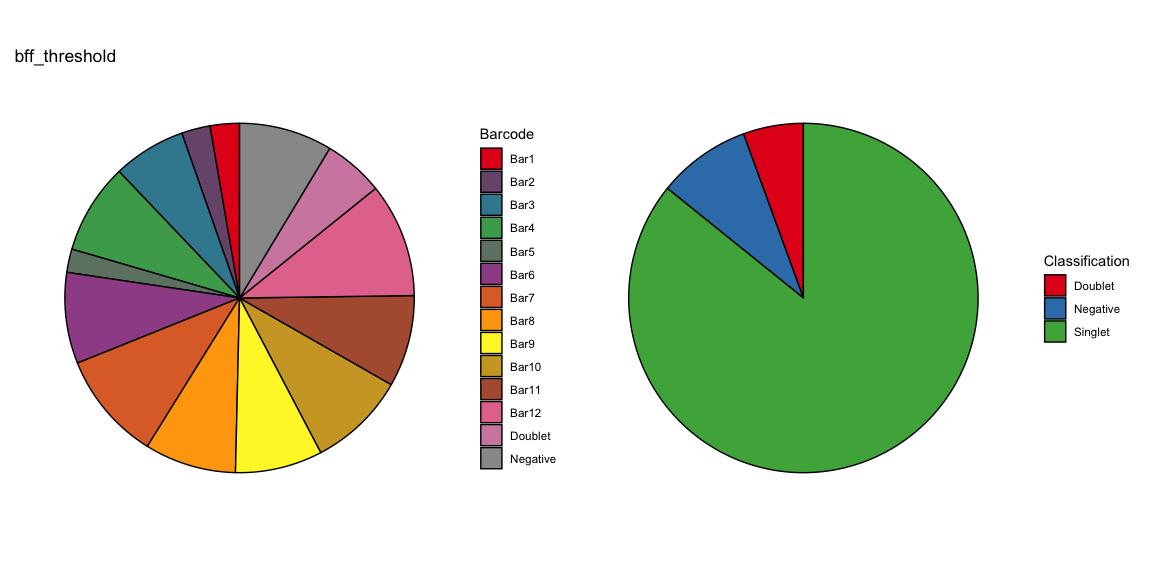
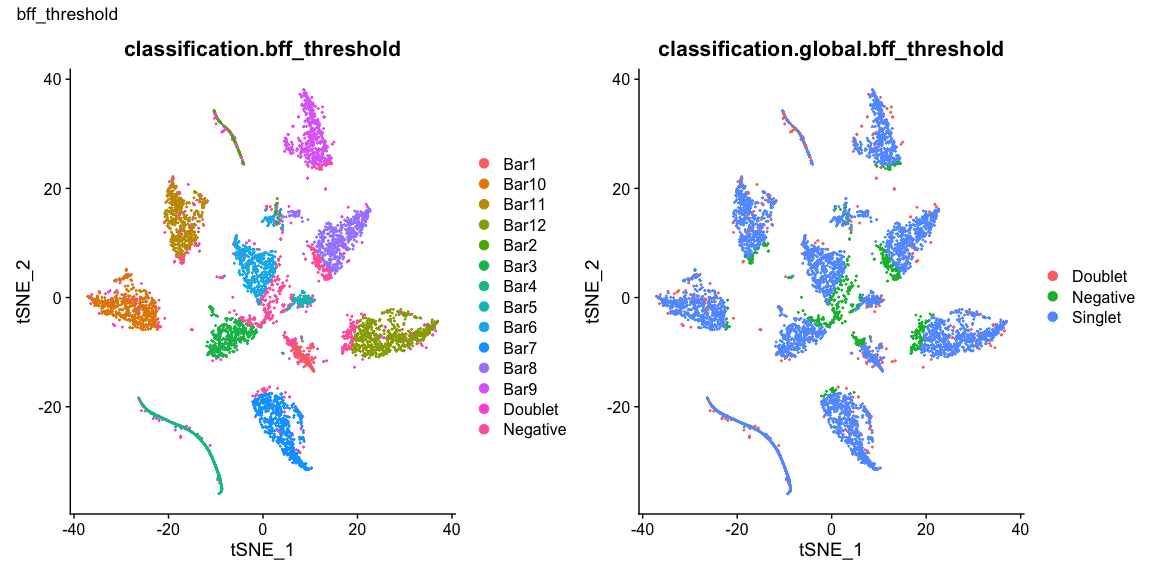
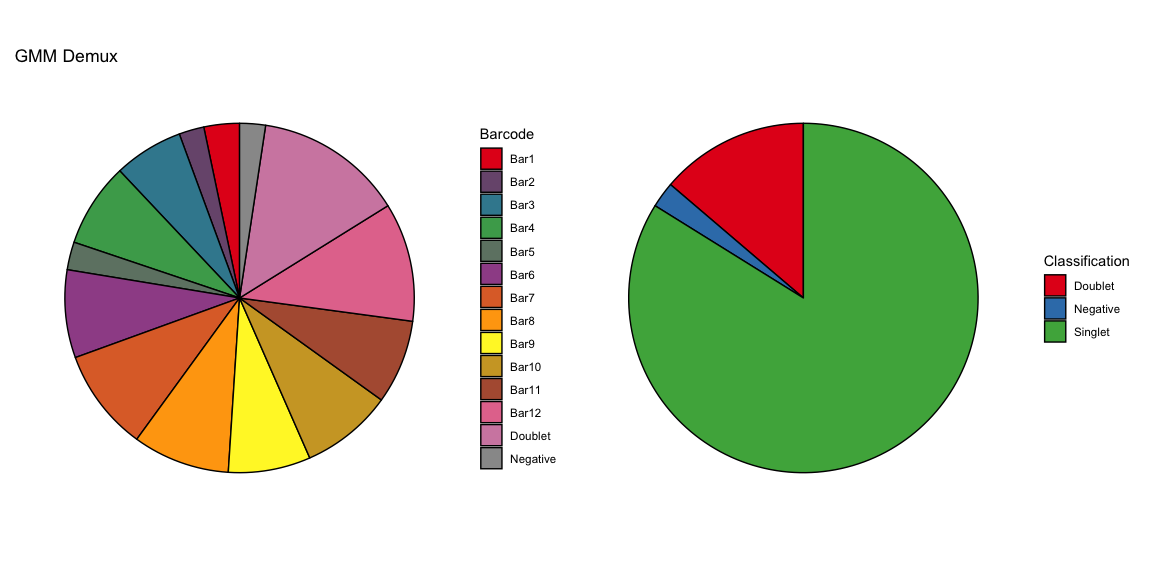
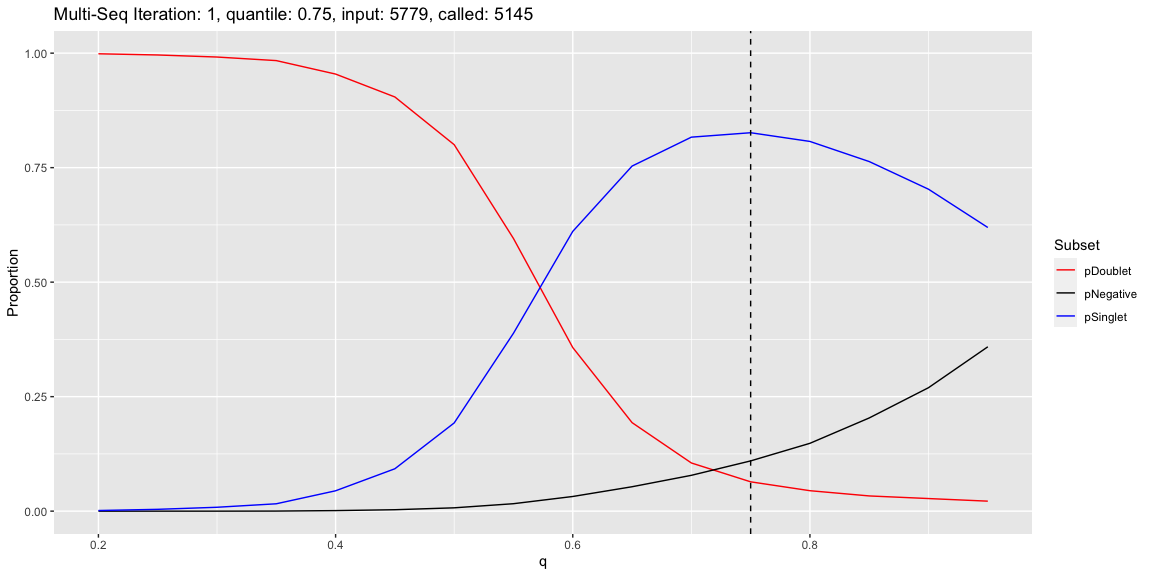
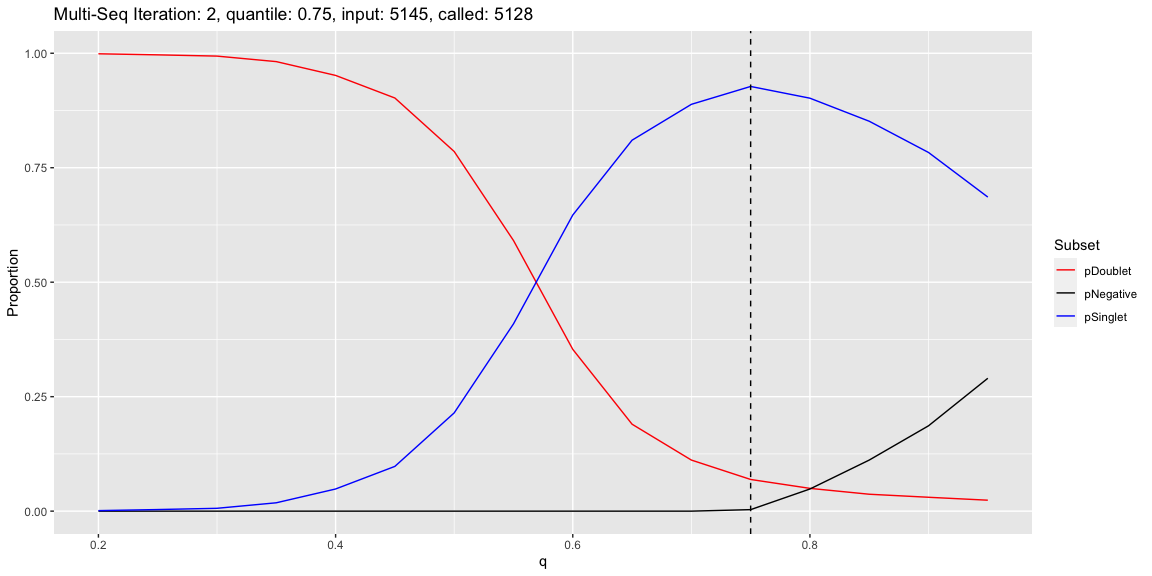

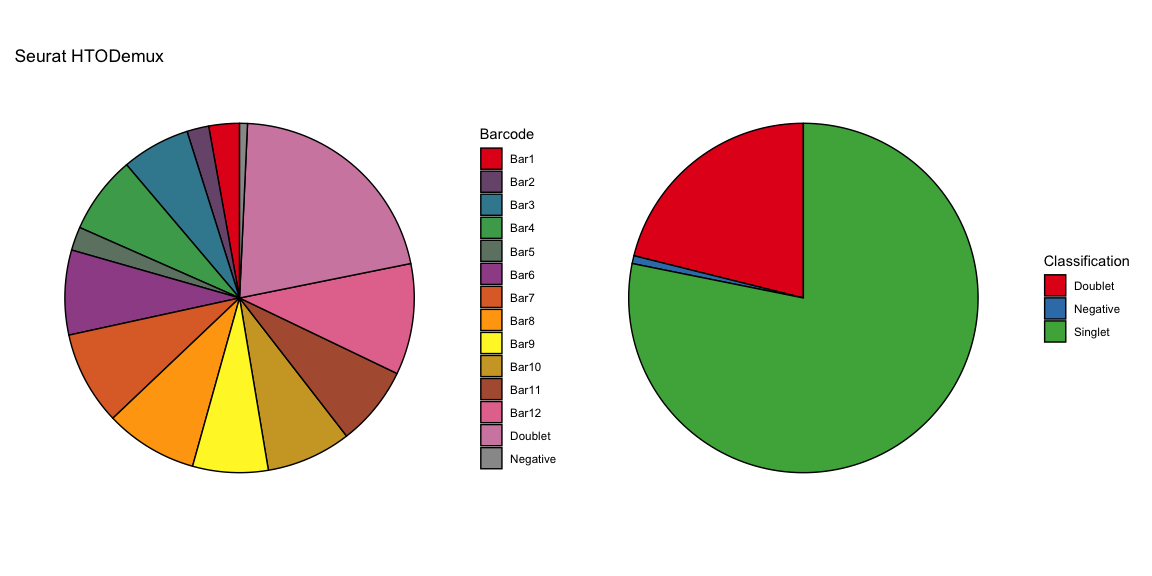
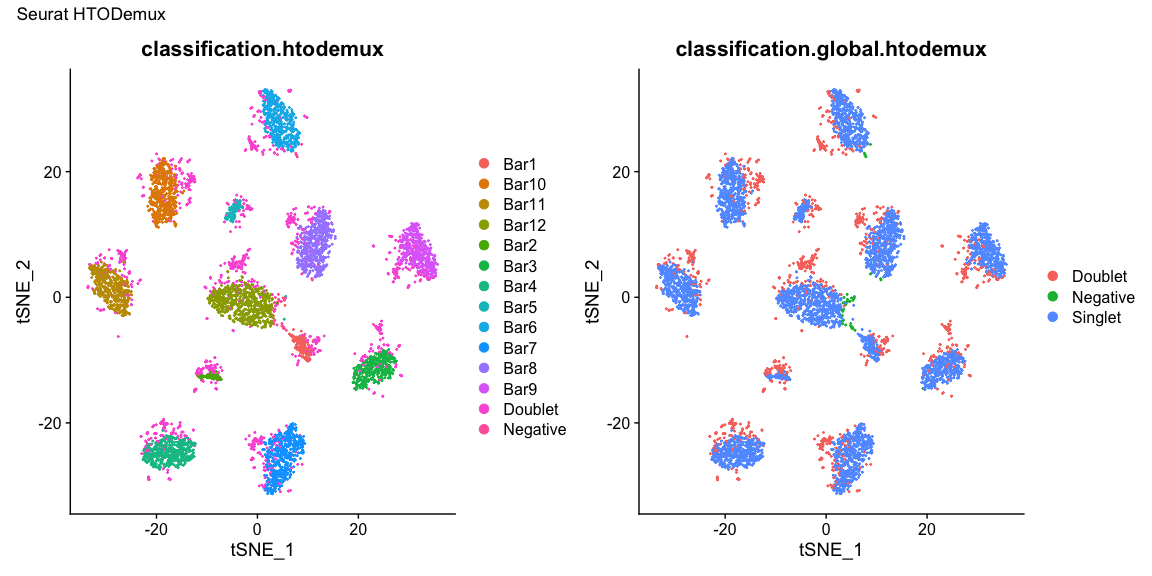
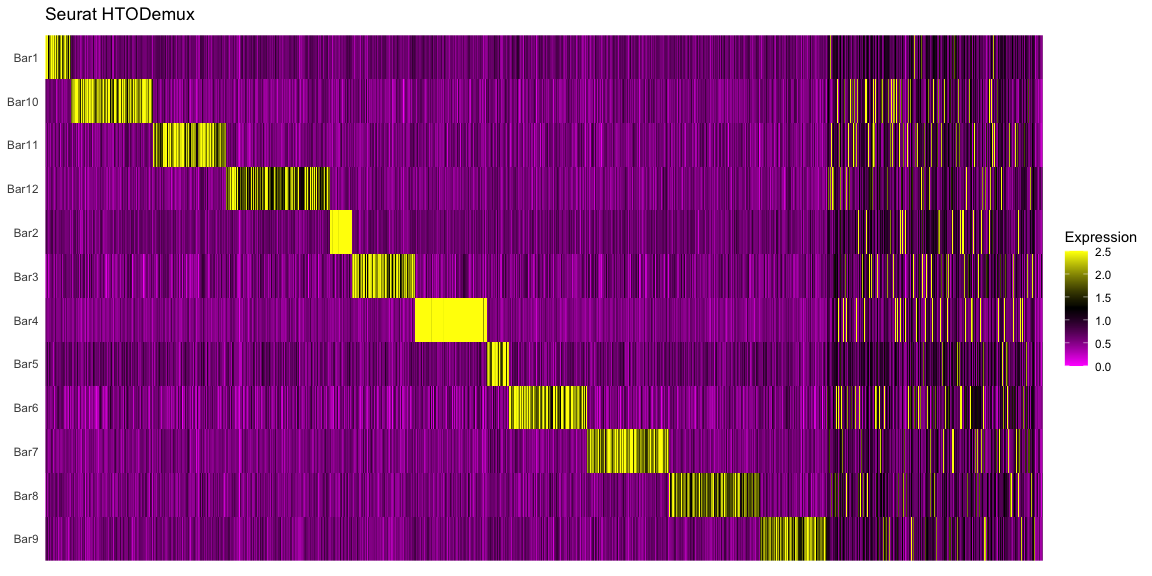
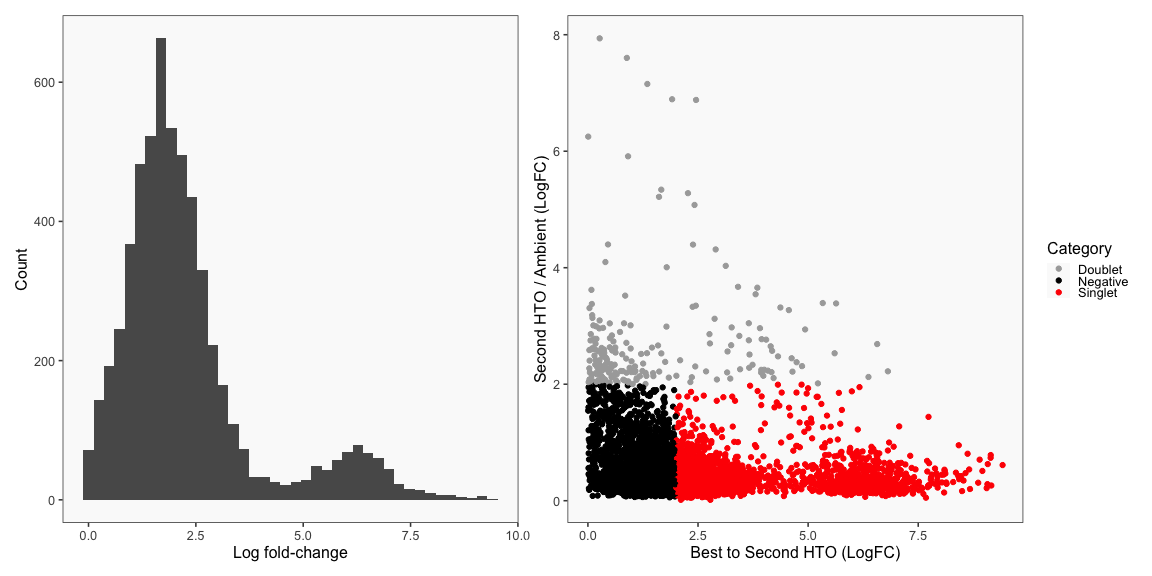
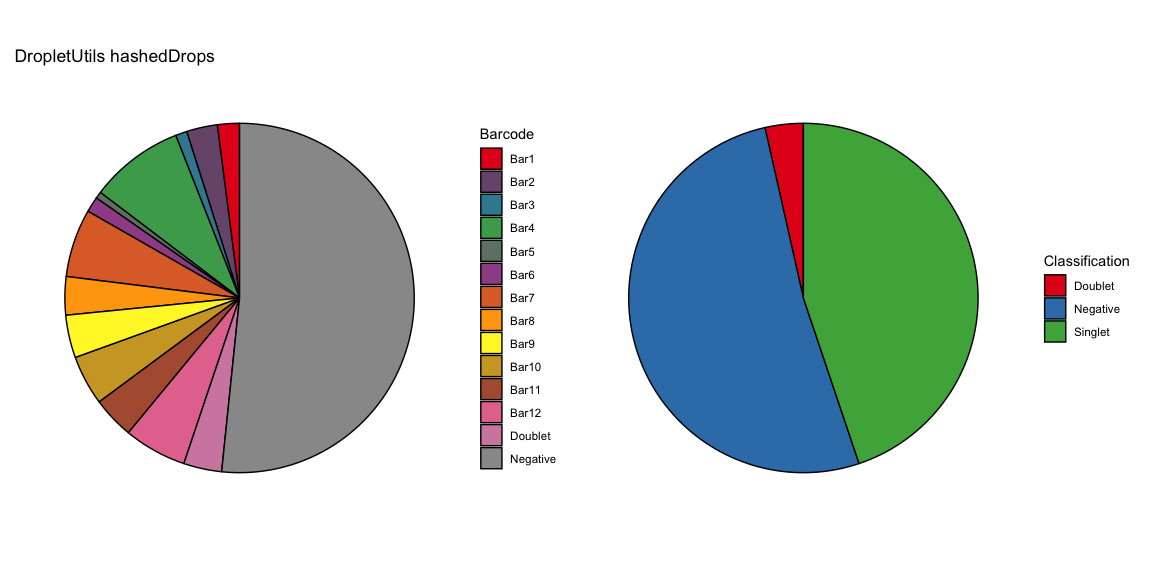
Summary of Calls
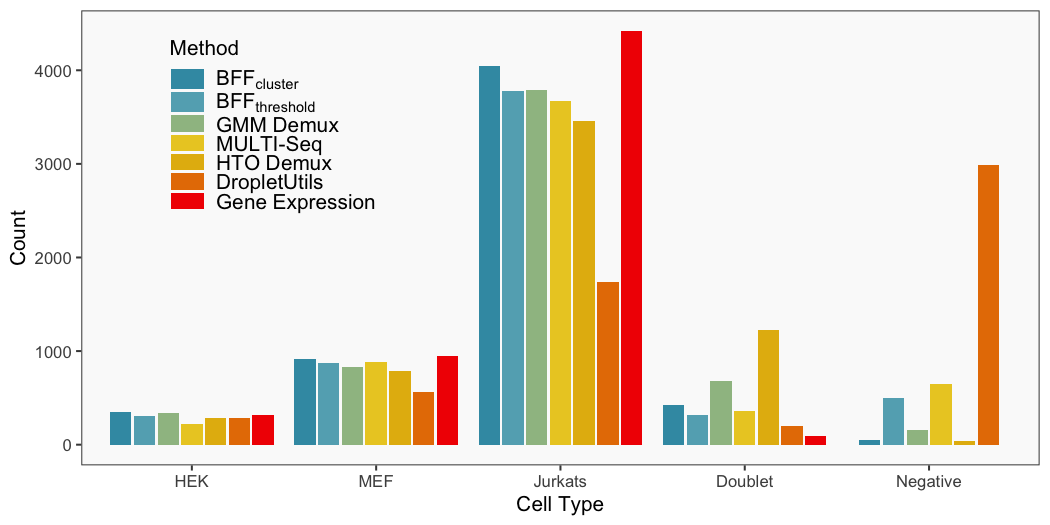
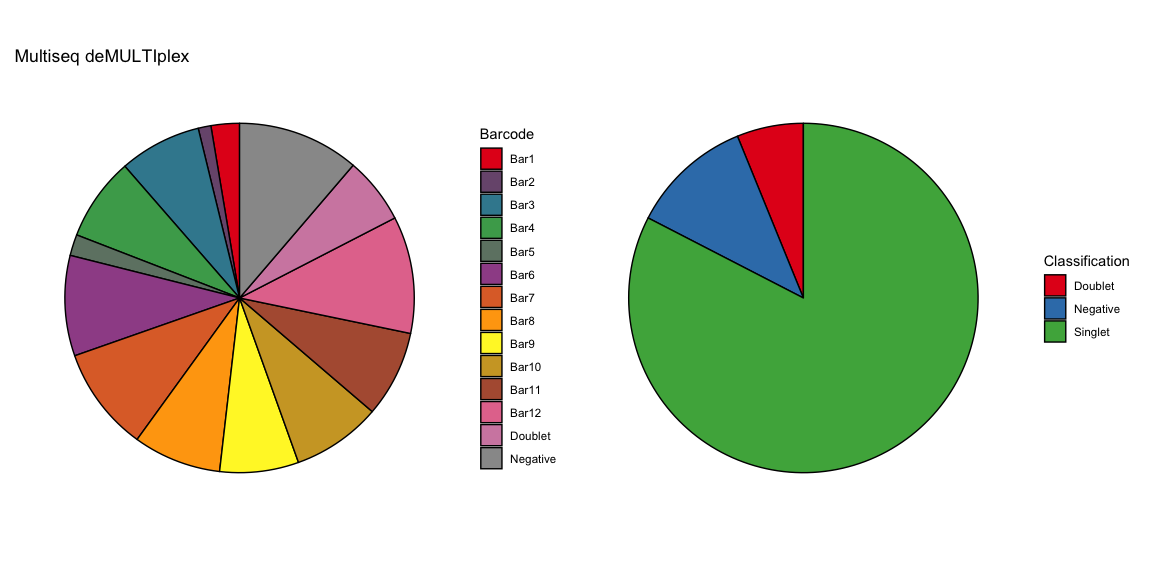
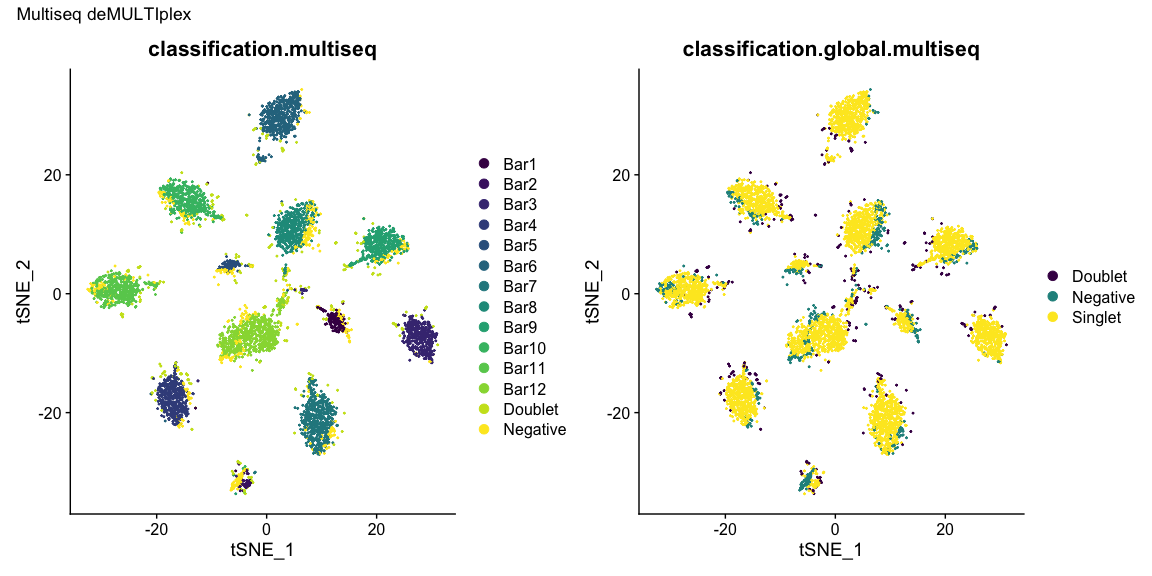
After all of the demultiplexing algorithms have run, the classifications are summarized as in these plots.
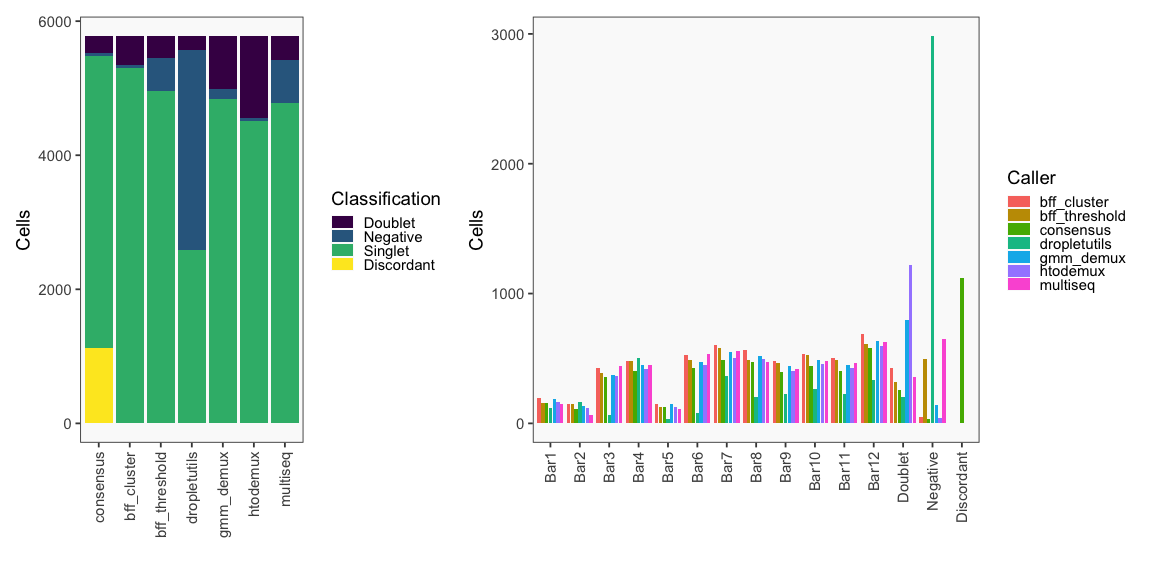
The classification summary above is related to the classification summary in the BFF paper (shown again below) because the HEK sample is composed of Bar1 and Bar2 droplets, the MEF sample is composed of Bar3 and Bar4 droplets, and the Jurkats sample is composed of droplets assigned to the remaining barcodes.